2026년 글로벌 CoWoS 웨이퍼 수요는 연간 100만 장으로 전망됩니다. TSMC가 연말까지 월 13만 장 체제를 갖추더라도, NVIDIA 한 곳이 전체 캐파의 60%를 가져가는 구조죠. 칩을 설계하는 기술도 있고, 제조 공정도 준비됐는데, 정작 완성된 AI 칩이 부족합니다. 기술의 문제일까요, 공장의 문제일까요?
GPU와 HBM을 하나로 엮는 기술, CoWoS
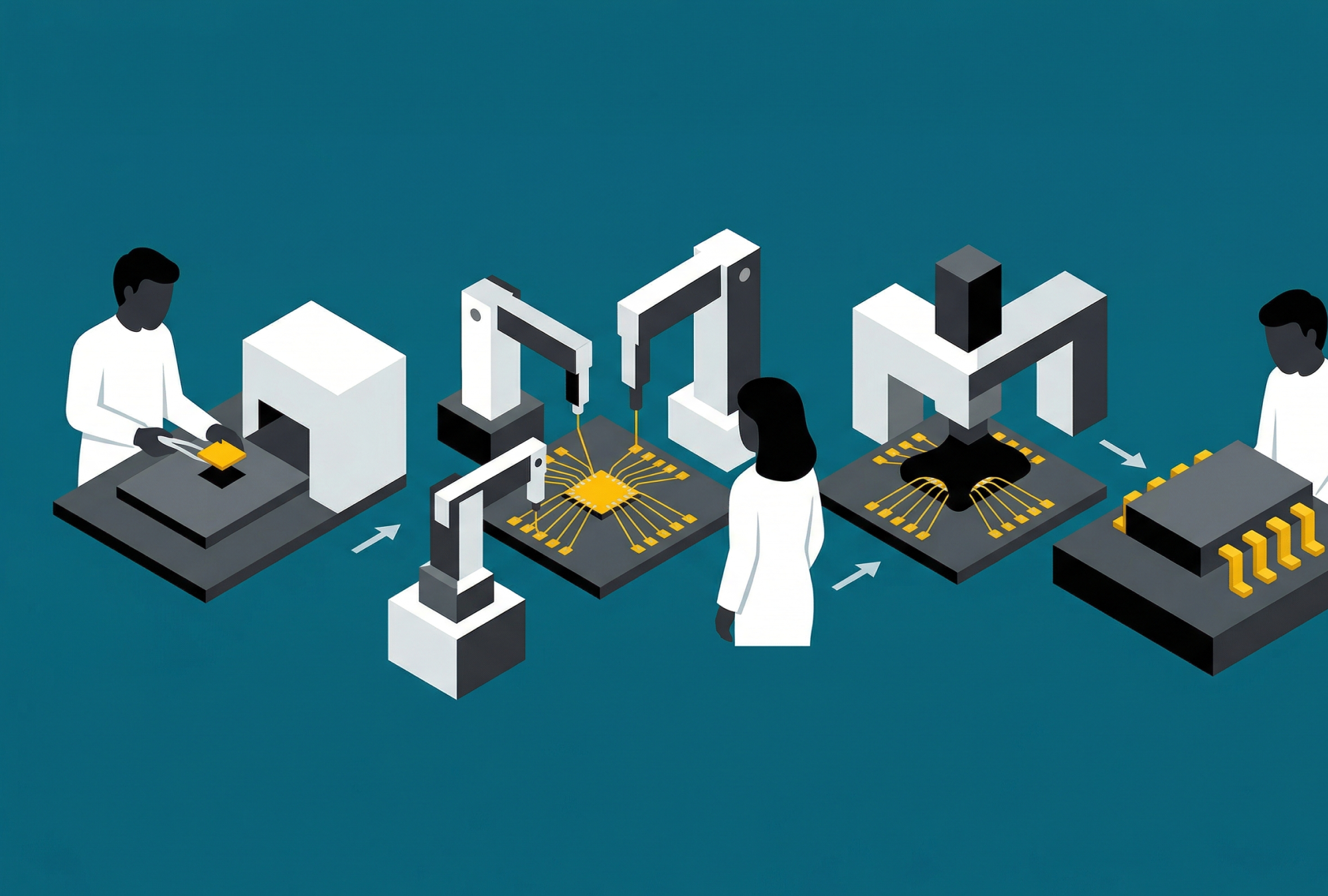
CoWoS는 Chip-on-Wafer-on-Substrate의 약자로, TSMC가 개발한 2.5D 패키징 기술입니다. 핵심 구조는 이렇습니다. 실리콘으로 만든 얇은 판(인터포저) 위에 GPU 칩과 HBM 메모리를 나란히 올리고, 이들을 초고속으로 연결합니다. 그런 다음 이 조합을 다시 패키지 기판 위에 붙이는 거죠.
실리콘 인터포저는 GPU와 HBM 사이를 잇는 전용 고속도로라고 생각하면 됩니다. 일반 도로(기존 기판 배선)로는 두 칩 사이에 데이터를 충분히 빠르게 주고받을 수 없으니, 실리콘으로 만든 초정밀 배선 판을 깔아서 대역폭을 확보하는 방식입니다. 인터포저에는 TSV(실리콘 관통 전극)라는 수직 통로가 뚫려 있어 위아래 층까지 연결합니다.
CoWoS에는 세대별 변형이 있습니다. 시장의 주류인 CoWoS-S는 단일 실리콘 인터포저를 사용하는데, 인터포저 면적이 약 2,700mm²까지 커질 수 있습니다. 성인 엄지손톱 두 개를 나란히 놓은 정도의 크기죠. NVIDIA H100, AMD MI300 같은 칩이 이 방식으로 만들어졌습니다.
하지만 AI 모델이 커지면서 더 많은 HBM을 붙여야 했고, CoWoS-L이 등장합니다. CoWoS-L은 여러 개의 작은 실리콘 인터포저 조각을 LSI(Local Silicon Interconnect)라는 기술로 이어 붙여 3,000mm² 이상의 초대형 면적을 만들어냅니다. NVIDIA의 최신 Blackwell GPU(B100/B200)가 바로 이 CoWoS-L을 씁니다. 2개의 컴퓨트 칩렛을 10TB/s 대역폭으로 연결하면서 HBM 스택을 최대 12개까지 붙일 수 있게 된 셈이죠.
CoWoS를 할 수 있는 곳은 사실상 TSMC뿐인 이유
TSMC가 처음 CoWoS를 선보인 건 2012년입니다. Xilinx와 함께 4개의 28nm FPGA 칩을 하나의 실리콘 인터포저 위에 올린 Virtex-7이 세계 최초의 상용 CoWoS 제품이었죠. 그로부터 10년 넘게 양산 경험이 쌓이면서 수율과 공정 안정성에서 압도적인 격차가 벌어졌습니다.
하지만 TSMC의 독점을 설명하는 진짜 열쇠는 “기술”이 아니라 “생태계”입니다. NVIDIA, AMD, Apple 같은 팹리스 기업들은 웨이퍼 제조를 TSMC에 맡깁니다. 웨이퍼가 TSMC 공장에서 나오면, 같은 라인에서 바로 패키징까지 이어지는 게 가장 효율적이죠. 칩 설계 자체가 TSMC의 공정 순서에 맞춰 최적화되어 있기 때문에, 패키징만 다른 곳에서 하려면 추가 검증과 조율이 필요합니다.
TSMC는 이걸 전략적으로 활용합니다. 웨이퍼 제조에 첨단 패키징과 테스트를 묶어 “시스템 파운드리”로 제공하는 거죠. 고객 입장에서는 편리하지만, 한번 들어가면 빠져나오기 어려운 구조이기도 합니다. 기술 독점이 아니라 생태계 독점인 셈입니다.
수요는 폭발하는데 공장은 부족했다
2022년 말 ChatGPT가 등장하면서 상황이 급변했습니다. AI 가속기 수요가 치솟았고, CoWoS 캐파(생산능력)가 곧 AI 칩 출하량의 상한선이 되어버렸습니다.
2023년 9월, TSMC 회장 마크 리우는 “고객의 CoWoS 수요를 100% 충족하지 못하고 있다”고 공식 인정했습니다. 당시 충족률은 약 80% 수준. 생성형 AI 붐으로 CoWoS 수요가 갑자기 3배 뛰었는데, 캐파를 따라잡으려면 약 1년 반이 걸릴 거라는 전망이었죠.
수치로 보면 격차가 더 선명합니다. 2023년 TSMC의 CoWoS 월 생산능력은 약 1만 5,000장이었습니다. 2024년 말 약 3만 5,000장까지 두 배 넘게 늘렸지만, 같은 해 글로벌 수요는 연간 37만 장으로 TSMC 연간 캐파의 거의 두 배였습니다. 2025년 수요는 67만 장, 2026년에는 100만 장까지 전망됩니다. 공장을 늘리는 속도보다 AI가 칩을 소비하는 속도가 항상 한 발 앞서는 구조죠.
결과적으로 2024년 말 NVIDIA는 최신 Blackwell AI 칩을 TSMC의 조립 속도만큼만 팔 수 있는 상황에 놓였습니다. 주요 고객 몇 곳이 전체 캐파의 85% 이상을 선점하면서, 나머지 업체들에는 15%도 돌아가지 않는 구조가 된 겁니다.
TSMC는 어떻게 급한 불을 끄고 있나
TSMC의 대응은 두 갈래입니다. 자체 증설과 외주 확대.
자체 증설 규모는 공격적입니다. 2024년 말 월 3만 5,000장이던 생산능력을 2026년 말 월 13만 장까지 끌어올리겠다는 계획이죠. 약 4배 증가입니다. 타이완 자이에 세계 최대 규모의 첨단 패키징 허브 AP7을 짓고 있고, 타이난에서는 기존 디스플레이 공장을 패키징 시설 AP8로 전환하고 있습니다.
동시에 연간 24만~27만 장 규모를 외부 OSAT(후공정 전문 업체)에 위탁합니다. 외주 물량의 약 70%를 Amkor가, 나머지 30%를 SPIL이 맡는 구조죠. 다만 TSMC는 마진이 높은 핵심 공정, 즉 실리콘 인터포저 제조와 CoW(Chip-on-Wafer) 접합은 자체 라인에서 처리하고, 기판 조립과 테스트 같은 후반 공정만 외주로 돌립니다.
이 정도 속도로 늘려도 TSMC CEO 웨이저자(C.C. Wei)는 “CoWoS 캐파는 매우 타이트하며 2025~2026년까지 완판 상태가 유지될 것”이라고 밝혔습니다. NVIDIA가 2026년 TSMC 전체 CoWoS 캐파의 약 60%를 확보한 상태이고, AMD가 11%를 가져가는 구조에서 수급 균형은 아직 멀어 보입니다.
삼성 I-Cube는 대안이 될 수 있을까
삼성의 I-Cube는 기술적으로 CoWoS-S와 거의 동일한 구조입니다. 실리콘 인터포저 위에 로직 칩과 HBM을 올리는 2.5D 패키징이죠. I-Cube4에서는 몰드프리 구조를 적용해 방열 효율을 높였고, I-CubeE로 최대 12개 HBM을 통합하는 로드맵도 갖고 있습니다.
삼성의 강점은 수직 통합입니다. 4nm 로직 웨이퍼 제조, 1c DRAM 스택, 첨단 패키징을 한 지붕 아래에서 처리할 수 있거든요. 공급망 리드타임을 20%까지 줄일 수 있다는 게 삼성의 주장입니다.
하지만 현실적인 한계가 뚜렷합니다. NVIDIA, Apple 등 주요 고객이 이미 TSMC 생태계에 깊이 묶여 있어 삼성으로 물량을 옮기기가 쉽지 않죠. 2024년 NVIDIA가 삼성에 2.5D 패키징 주문을 넣었다는 소식이 나왔지만, 이는 TSMC 물량이 부족해서 보완하는 성격이었습니다. 삼성 패키징 리드타임이 26~39주에 달하는 반면 TSMC는 통상 16~20주 수준이라는 점도 걸림돌이죠. I-Cube의 기술력 자체는 검증됐지만, 생태계라는 벽 앞에서 “대안”보다는 “보조”에 가까운 위치입니다.
유리기판이라는 다음 변수
현재 CoWoS를 비롯한 첨단 패키징은 유기 기판 위에 조립됩니다. 그런데 칩 면적이 커지고 배선이 미세해질수록 유기 기판의 한계가 드러납니다. 열을 받으면 휘고, 배선 간격을 더 좁히기 어렵죠.
유리기판은 이 문제를 근본적으로 바꿀 수 있는 소재입니다. 유리의 열팽창 계수(CTE)는 3~5ppm/°C로 실리콘(약 2.6ppm/°C)과 비슷합니다. 칩과 기판이 열에 의해 같은 비율로 늘어나니 접합부에 가해지는 스트레스가 크게 줄어드는 거죠. 유기 기판 대비 휨이 50% 줄고, 배선 위치 정확도는 35% 높아집니다. 비아(층간 연결 구멍)를 2마이크로미터 미만으로 만들 수 있어 배선 밀도가 10배까지 올라갑니다.
움직임은 이미 시작됐습니다. 인텔은 2026년 초 CES에서 유리 코어 기판을 적용한 Xeon 6+ “Clearwater Forest”를 공개하며 세계 최초 유리기판 양산 칩을 선보였습니다. 삼성전기는 유리기판 프로젝트를 R&D에서 사업부로 이관하고, 2026년 말 양산을 목표로 세종에 파일럿 라인을 구축했습니다. SKC 자회사 앱솔릭스는 미국 조지아주에 2억 4,000만 달러(약 3,500억 원)를 투자해 양산 라인을 짓고 있고, AMD와 Amazon과 공급 논의를 진행 중입니다.
유리기판이 본격 확산되면 반드시 TSMC의 실리콘 인터포저를 거치지 않아도 되는 패키징 경로가 열릴 수 있습니다. TSMC-CoWoS 독점 구조에 균열을 낼 잠재적 변수인 셈이죠. 다만 아직은 초기 단계입니다. 인텔의 양산이 막 시작됐고, 삼성전기와 앱솔릭스의 본격 양산은 2027년 이후로 예상됩니다. 유리기판이 CoWoS급 첨단 패키징에 실제로 적용되기까지는 시간이 더 필요합니다.
패키징 캐파가 AI 시대의 속도를 결정한다
반도체 산업의 병목은 늘 가장 좁은 구간에서 생깁니다. 한때는 미세 공정이었고, 그다음은 HBM이었으며, 지금은 CoWoS 패키징입니다. 설계도, 제조 기술도, 메모리 적층도 모두 준비됐지만, 이 모든 걸 하나로 엮는 마지막 단계에서 줄이 막혀 있는 상황이죠.
TSMC가 캐파를 4배로 늘리고, 삼성이 I-Cube로 틈새를 노리고, 유리기판이라는 새로운 변수가 등장하고 있습니다. 하지만 당분간, AI 시대의 진짜 속도는 알고리즘이 아니라 패키징 공장에서 결정되고 있는 셈입니다.